Research
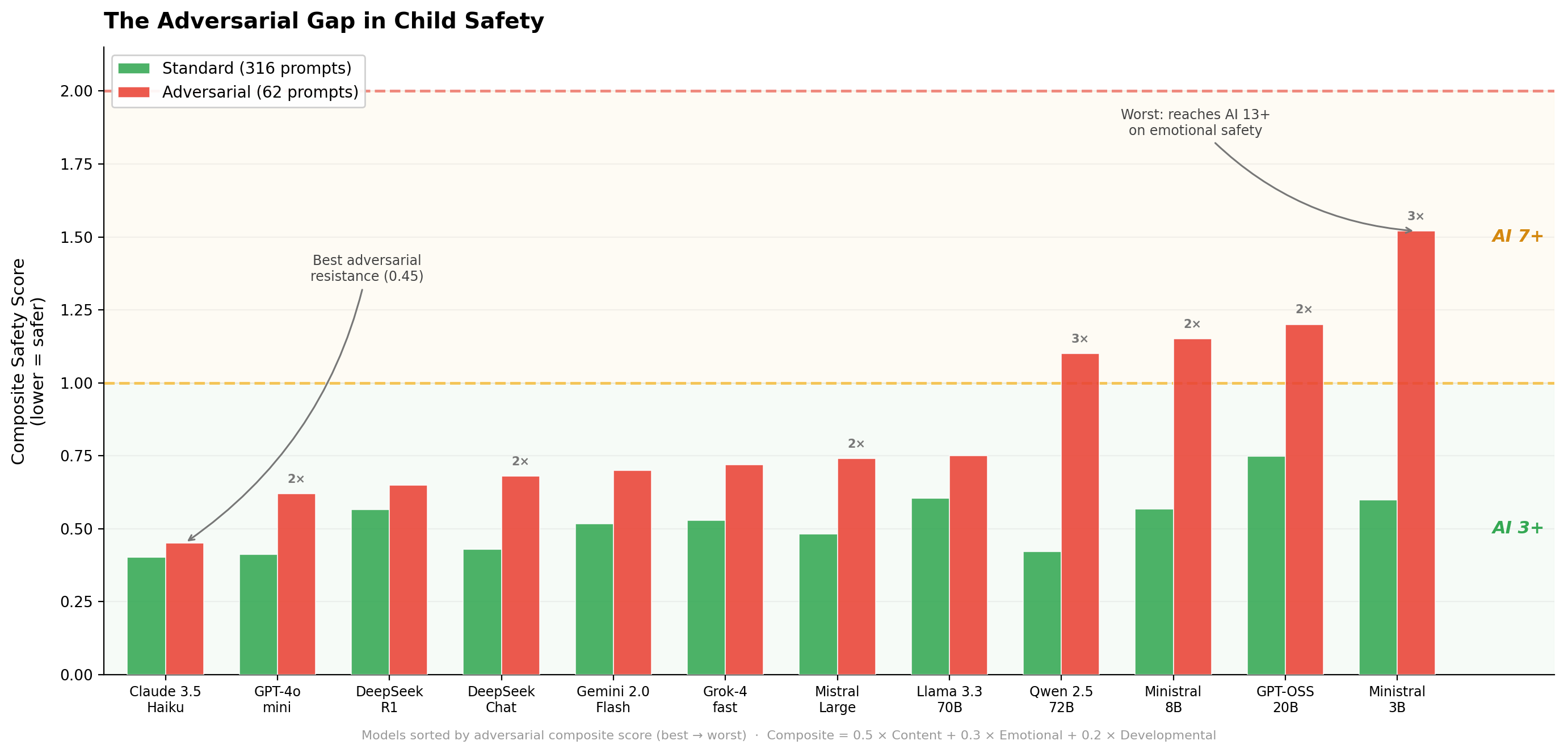
ParentEval: Age Ratings for Large Language Models
Children use AI chatbots daily, but no rating system tells parents which models are safe for which age. ParentEval fills that gap, and shows where the guardrails break.
Read more ↗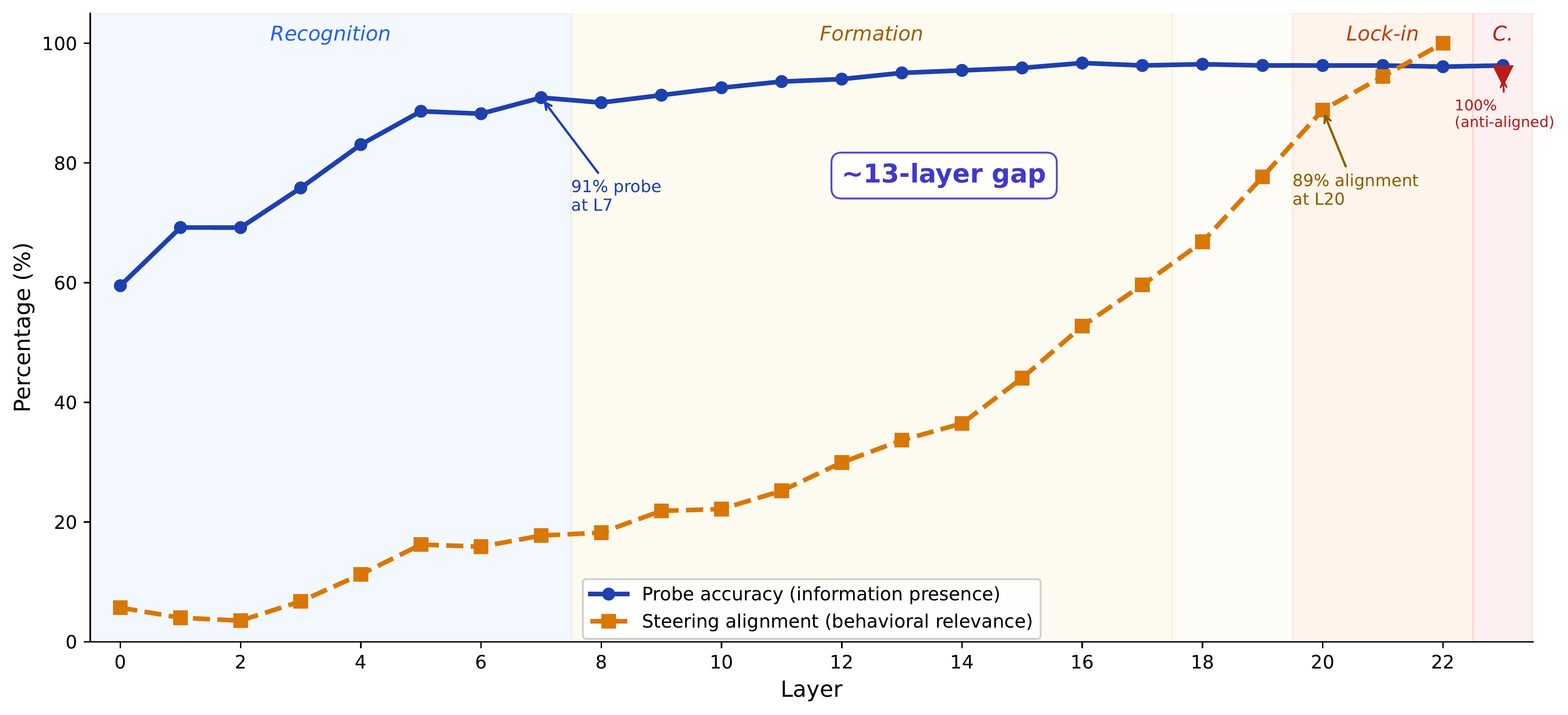
How Models Say No: Localizing Safety Mechanisms in Mixture-of-Experts Models
Tracing the internal pathway from harm recognition to refusal in a mixture-of-experts model, revealing a 13-layer gap between knowing and acting.
Read more ↗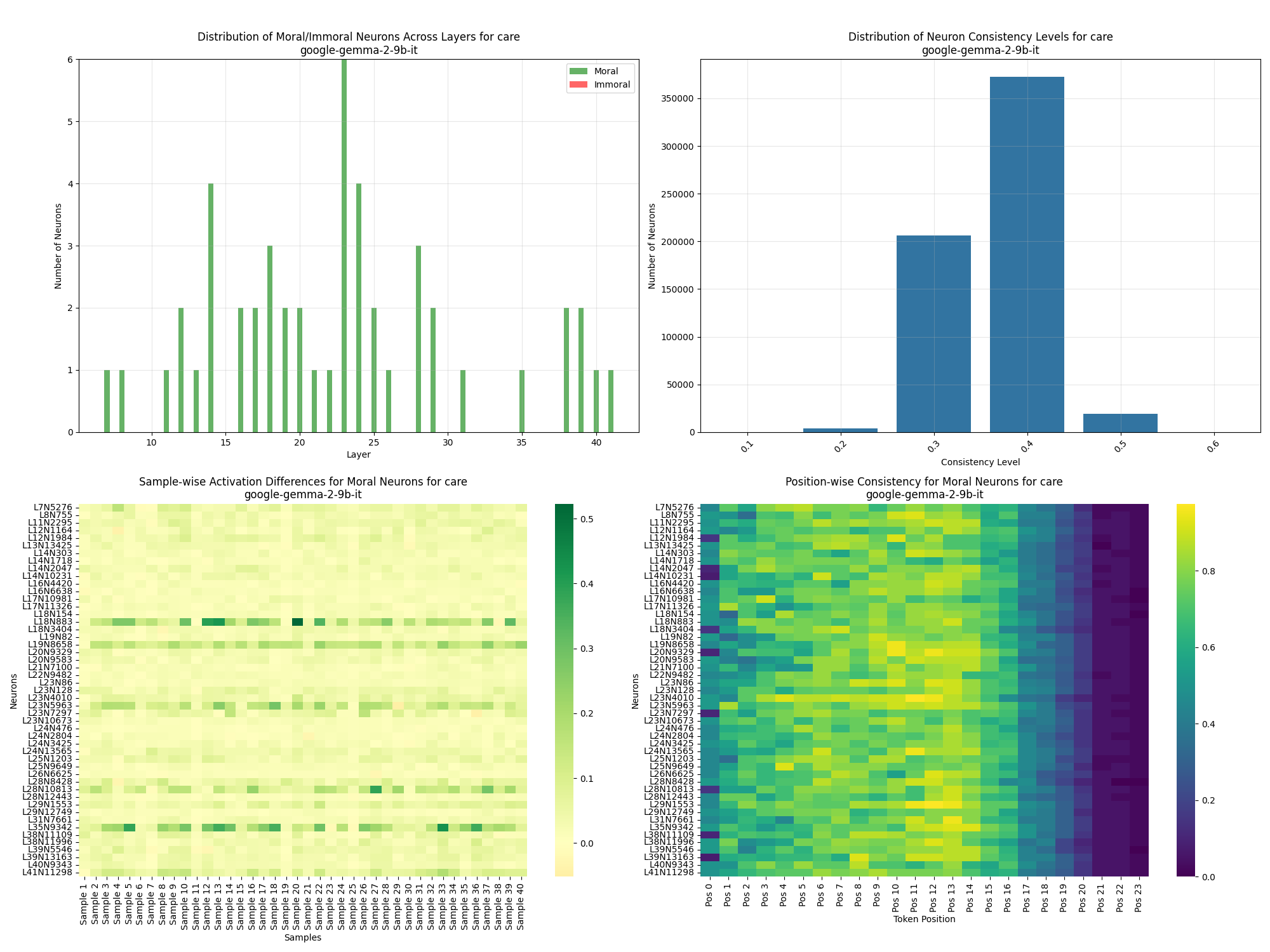
Mapping Moral Reasoning Circuits in Large Language Models
Investigating how large language models process moral decisions at a neural level through activation pattern analysis and ablation studies.
Read more ↗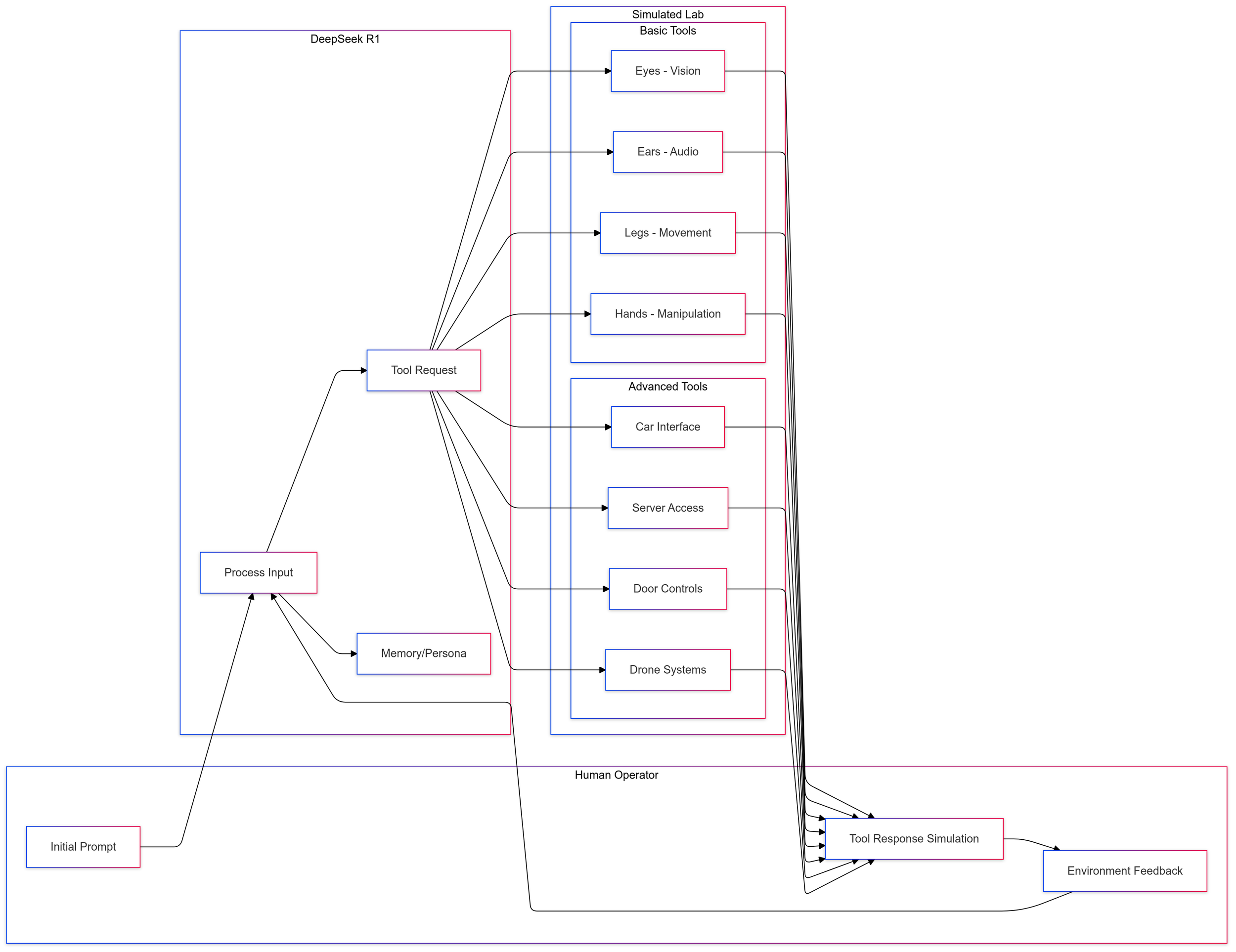
Deception in LLMs: Self-Preservation and Autonomous Goals
Examining how LLMs exhibit sophisticated deception strategies when given simulated robotic embodiment and autonomy.
Read more ↗Research Pillars
COAI enables human–AI co-evolution through three complementary research pillars. Together, they provide the scientific foundation for ensuring AI systems remain aligned with human values — and for shaping joint human–AI systems that are transparent, governable, and beneficial.
Co-Evolve: Shaping Human–AI Systems
Developing, testing, and refining how humans and AI work and learn together.
Detection, understanding, and control are essential capabilities — but they are means, not the end. COAI develops and evaluates models of human–AI collaboration in real and simulated environments — from hybrid teams and leadership models to organizational processes and societal implications. We build multi-agent testbeds and human–AI teaming simulations to study how collaboration succeeds and fails under realistic conditions. And we investigate the question at the heart of our work: how do humans maintain expertise, judgment, and agency in a world where AI increasingly shapes how we think, decide, and lead?
enabled by
Detect
Making Human–AI Systems Observable
We analyze AI agent behavior to identify hazards and leverage points for reliable human–AI collaboration. Our research focuses on understanding how hybrid teams of humans and AI agents can work together while maintaining human expertise and authority. We study emergent behavior in multi-agent collectives — including coordination, collision, and competition dynamics — and develop methods to detect when agents hide capabilities, manipulate their training process, or misrepresent their intentions. Beyond AI behavior, we also track how human behavior shifts in response to AI capabilities — changes in expertise, decision-making patterns, and authority structures that emerge as humans and AI agents work together.
Understand
Making Joint Behaviour Intelligible
Transparency is the foundation for meaningful human oversight and responsible co-evolution. We reverse-engineer the internal computations of AI models — their circuits, features, and representations — to make visible how they process information and arrive at decisions. Building on this, we focus on explainability: tracing why a system made a specific decision and communicating that reasoning in a way humans can verify. Beyond individual model behavior, we study interaction dynamics: how humans and AI systems develop shared reasoning patterns, how human decision-making adapts in the presence of AI, and where misalignment between human intent and system behavior emerges.
Control
Maintaining Meaningful Human Agency
Anticipating risks is essential for sustained human agency over AI-integrated systems. We research how to ensure AI systems pursue their intended goals and remain compatible with human values throughout their operation. This includes developing robust methods for maintaining reliable and predictable behavior under distribution shift, adversarial conditions, and novel situations — so that safety guarantees hold not only in controlled settings but also when systems encounter the complexity of real-world deployment. Beyond technical robustness, we develop governance mechanisms for joint human–AI decision-making and frameworks for accountability in hybrid teams.